En la sección pasada hablábamos del patrón Service Registry, y analizábamos como mediante este patrón era posible tener un catálogo actualizado de todos los Servicios disponibles, sin embargo, poco o nada de provecho podemos tener de un registro si no tomamos ventaja de este registro para crear aplicaciones mucho más robusta, es por ello que en esta sección analizaremos el patrón Service Discovery el cual hace complemento con el patrón Service Discovery, por lo que si te saltaste la unidad anterior, te recomiendo que regreses antes de continuar con esta unidad, ya haremos uso de los conceptos aprendidos.
Problemática
Uno de los mayores problemas cuando trabajamos con servicios, es saber su ubicación física, ya que cada servicio responde en un dirección y puerto específico, por lo que recurrimos en técnicas como archivos de configuración que nos permite guardar la dirección de cada servicio por ambiente, de esta forma, tenemos un archivo con la propiedades de desarrollo, de calidad y producción, lo cual es una estrategia efectiva si trabajamos con un hardware específico, es decir, tenemos el control del servidor sobre el cual desplegamos nuestros componentes. Por ejemplo:
Pero que pasa en arquitecturas Cloud, donde cada componente puede cambiar dinámicamente de IP o puerto, ya sea por fallas o por agregar o quitar instancias según la demanda de nuestra aplicación (Nube elástica)
Nuevo concepto: Elasticidad
En arquitecturas Cloud, la elasticidad es la capacidad de la nube para crecer o disminuir en recursos a medida que la demanda aumenta o disminuye, por lo que es posible aprovisionar nuevos servidores o ampliar la capacidad de procesamiento de los existentes a demanda, sin necesidad la intervención humana.
Entonces, si la nube es elástica, implica que nuevas instancias de un servicio se den de alta o las existentes se apaguen, además, cuando la nube se estira, crea nuevas instancias en IP random, lo cual hacer que un archivo de configuración fijo se vuelva obsoleto, ya que tendríamos que tener a una persona que este actualizando ese archivo cada vez que una instancia se de alta o de baja, lo cual es obviamente ineficiente y altamente propensa a errores.
Para comprender mejor este problema analicemos la siguiente imagen:
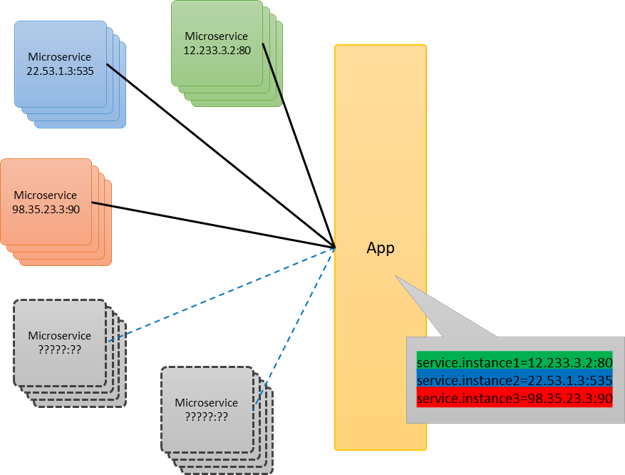
Problemática de no usar Service Discovery
En la imagen anterior podemos observar el problema que describimos hace un momento, es decir, una aplicación que tiene un archivo de configuración para ubicar la dirección física de cada instancia, sin embargo, hablábamos de la elasticidad de la nube, que permitía que nuevas instancias se aprovisionara, lo que provocaría que estas nuevas instancias fueran desconocidas por la aplicación hasta que alguien manualmente agregar estas nuevas instancias al archivo de configuración.
Otro problema que también se puede dar es que una instancia deje de responder o simplemente se elimina como parte de la elasticidad de la nube, lo que dejaría a la aplicación apuntando a una instancia del servicio que no está en capacidades de responder:
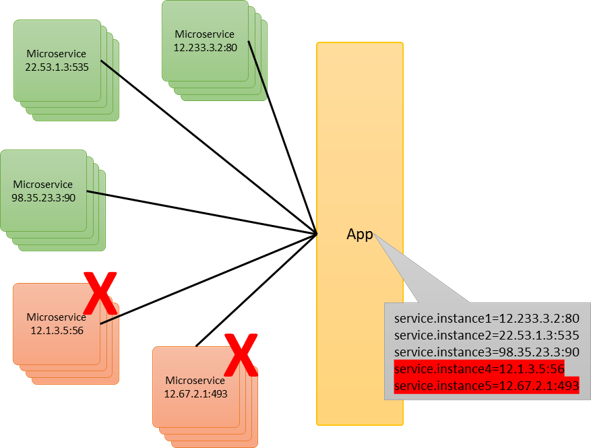
Contracción de la nube
Como puedes ver en la imagen, dos instancias del servicio han dejado de responder o simplemente se han dado de baja, dando como resultado que la aplicación nuevamente esté desactualizada, e incluso termine fallando, por intentar ejecutar servicios que no estén disponibles.
Estos dos ejemplos que te acabo de mostrar ocurren mucho en la vida real, sobre todo en temporadas de ventas altas, como el Black Friday, Navidad, o días festivos como día de la madre o incluso, lanzamientos de nuevos productos, por lo tanto, cualquiera de las configuraciones anteriores garantizará la operatividad con demanda fluctuante.
Solución
Para solucionar el problema de la ubicación de los servicios, es indispensable desacoplar la configuración de la ubicación de los servicios a un componente externo llamado Service Discovery, el cual es el encargado de determinar todas las instancias activas de los servicios por medio de un Registro central, el cual es nada menos que el Service Registry que analizamos en la sección pasado.
El Service Discovery es un componente que se encarga de recuperar del Service Registry todas las instancias de los servicios disponibles y realizar el balance de cargas, sin embargo, existen dos formas en la que este descubrimiento se pueda dar, del lado del cliente y del lado del servidor.
Descubrimiento del lado del cliente
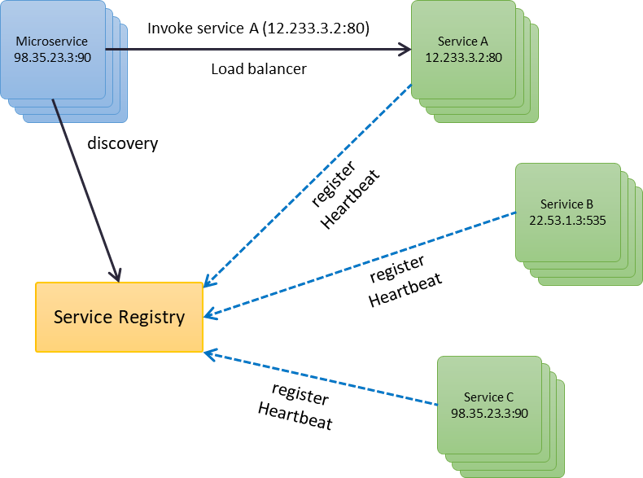
En el descubrimiento del lado del cliente, es el cliente el encargado de consultar al registro de los servicios disponibles, para posteriormente, el mismo realizar el balanceo entre las instancias disponibles:
Descubrimiento del lado del cliente
Para comprender la imagen anterior, es necesario listar como se dan los eventos. Lo primero que sucede es que los todos los servicios (lado derecho) se registran con el Service Registry, después del registro, estos continuaran mandando los latidos (hearbeat) para que el Service Registry los detecte como activos. En un segundo momento, el cliente (azul) requiere consumir el Service A, sin embargo, este no conoce la ubicación física del servicio, por lo que realiza una consulta al Service Registry para que le informe de todas las instancias disponibles (a este paso le conocemos como descubrimiento de servicios). Finalmente, el cliente tiene la dirección de todas las instancias disponibles, por lo que hace un balanceo de cargas de forma local y determina a que instancia realiza la invocación.
Un detalle a tomar en cuenta es que el cliente no requiere consultar al Registro la ubicación de los servicios cada vez que requiere hacer una llamada, en su lugar, el cliente puede guardar en cache la ubicación de todas las instancias disponibles, evitando tener que ir al registro con cada llamada, sin embargo, ese cache es válido solo por un corto tiempo, ya que después de un tiempo configurable, este consulta nuevamente al registro, para de esta forma tener actualizado el registro de servicios.
La principal ventaja de tener el descubrimiento del lado del cliente es que el cliente puede utilizar el algoritmo de balanceo que mejor se ajuste a sus necesidades, sin tener que depender de alguien que lo hago por él, por otro lado, ya que el cliente tiene en cache todas las instancias disponibles, podría seguir operando por un tiempo si se cae el Service Register, ya que no existe un solo punto de fallo, sin embargo, también tiene sus desventajas, y es que es necesario desarrollar la lógica de descubrimiento de servicios directamente en el cliente, por lo que será necesario desarrollar el descubrimiento para cada tecnología o framework específico.
Descubrimiento del lado del servidor
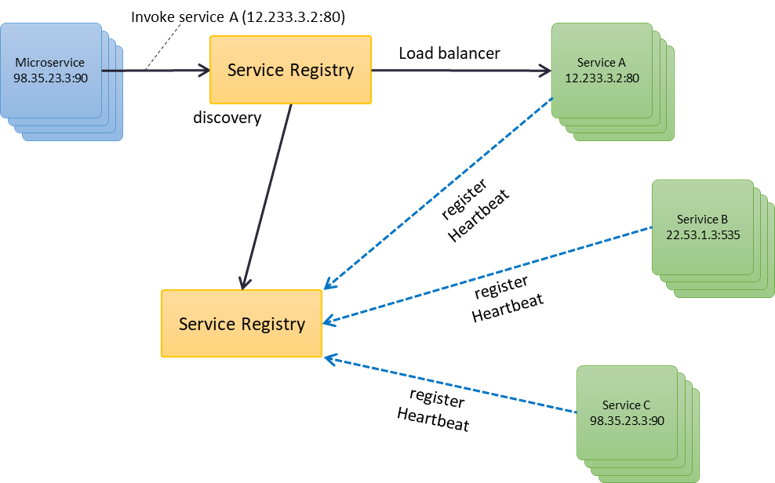
Como su nombre lo indica, en esta variación, el descubrimiento de los servicios se hace del lado del servidor, ocultando al cliente esta capacidad, de esta forma, el cliente se comunica a una única dirección la cual internamente hace el descubrimiento y el balanceo de cargas.
Descubrimiento del lado del servidor
Quiero que observes que en esta arquitectura interviene un elemento adicional, que es el balanceador de cargas, pues este permite, en primer lugar, proporcionar una dirección única, la cual pueda consumir el cliente, por otro lado, balancea la carga. Para lograr el balance, es el balanceador de cargas el que tiene que comunicarse con el Service Registry, para de esta forma conocer todas las instancias activas de un servicio.
La principal ventaja de esta variante es que el cliente no tiene que implementar la lógica para el descubrimiento de servicios ni la del balanceo de cargas, pues el solo ejecuta una sola URL y se olvida del resto. Sin embargo, tiene como desventajas que hay que implementar un balanceador de cargas, lo que hace que tengamos un elemento más que administrar y que creamos un único punto de falla, de esta forma, si se cae el balanceador de cargas perdemos toda comunicación con los servicios.
Conclusiones
Como hemos podido constatar, utilizar una estrategia de auto descubrimiento de servicios nos permite crear aplicaciones mucho más escalables, pues no dependemos de un servidor específico ni la IP o puerto que este nos asigne, sino todo lo contrario, ahora, podemos desplegar donde sea y como sea, al final, todos los servicios podrán ser localizados gracias al Service Discovery que por medio de Service Registry es posible ubicar y balancear la carga entre todas las instancias disponibles.
Al igual que el Service Registry, el Service Discovery es uno de los patrones más importantes a la hora de implementar arquitecturas de Microservicios o nativas para la nube, porque nos permite primero que nada desacoplarnos de los servidores físicos y, en segundo lugar, porque nos permite escalar rápidamente con tan solo levantar nuevas instancias.
Acerca de este libro
Todo lo que acabas de ver en este artículo es solo una pequeña parte del libro Introducción a la arquitectura de software, el libro más completo en español sobre arquitectura de software, donde cubrimos los temas más importantes para convertirte en un arquitecto de software profesional.
¿Quieres convertirte en arquitecto de software pero no sabes cuál es el camino adecuando? o simplemente no sabes que guía estudiar para convertirte en arquitecto de software, te invito a que veas mi libro: