Tener una traza clara de la ejecución de la aplicación es sin duda una de las cosas más importantes a tener en cuenta cuando diseñamos la aplicación, pues de eso depende encontrar errores y poder dar soluciones más rápidas a los clientes, pero sobre todo, nos permite saber con claridad que es lo que está haciendo y por donde está pasando la aplicación.
Problemática
Uno de los problemas más frecuentes cuando hablamos de arquitecturas distribuidas es obtener una trazabilidad de la ejecución de un servicio, ya que en este tipo de arquitecturas la ejecución de un servicio pasa por múltiples servicios, lo que hace complicado comprender lo que está pasado y tener un log detallados de lo que está pasando.
Además, en el caso de arquitecturas como Microservicios, es común tener múltiples instancias de un mismo componente, lo que hace que recuperar la traza de ejecución sea un verdadero dolor de cabeza.
Logs distribuidos
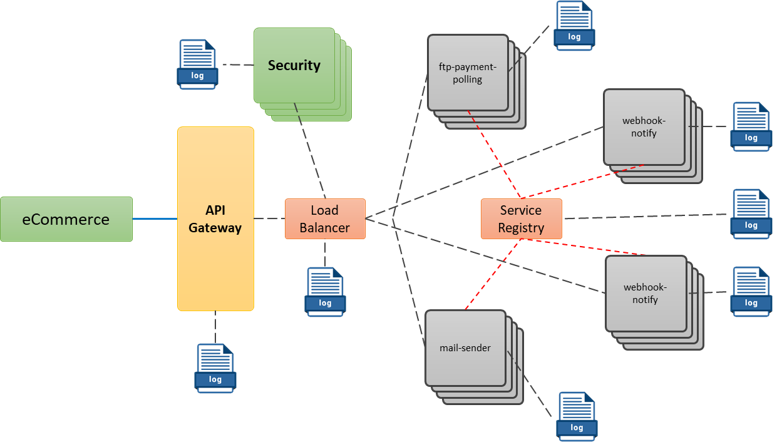
En la imagen anterior podemos ver más claramente el problema que mencionaba anteriormente, en el cual, cada servicio va dejando de forma local un log con el registro de la ejecución, por lo que si queremos tener una traza completa de un proceso, necesitamos recuperar el log de cada Microservicios, buscar por medio de la hora el log que corresponda a la ejecución y luego unificarlo, lo que puede ser una tarea verdaderamente complicado, sumado a esto, si tenemos múltiples instancias de cada servicio, es necesario abrir el log de todas las instancias para saber cuál fue la que proceso nuestra petición, pues si recordamos, el balanceo de cargas hace que sea imposible saber cuál fue la instancia de cada Microservicio que proceso nuestra solicitud.
Solo para darnos una idea de lo complicado que puede ser esto, analicemos la ejecución necesaria para crear una nueva orden desde la aplicación eCommerce:
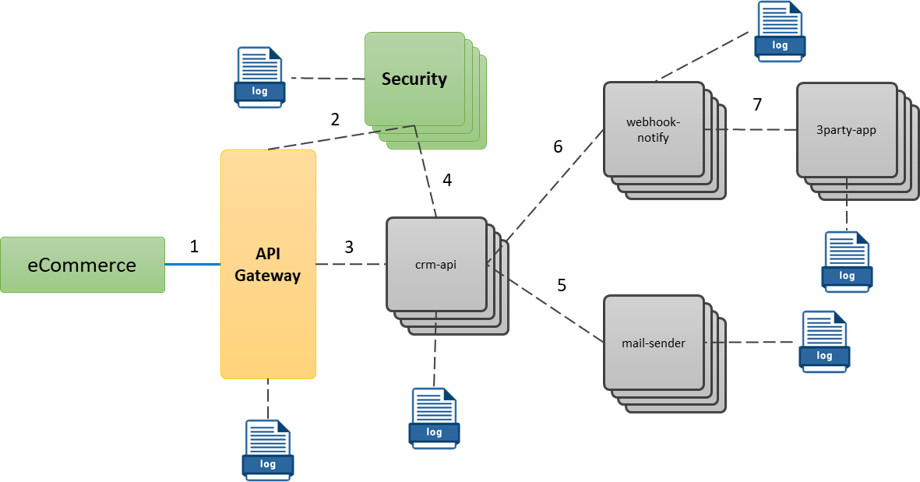
Flujo de ejecución para la creación de una orden
En la imagen podemos apreciar de forma enumerada los Microservicios que es necesario ejecutar para crear una solo orden, lo que implica que cada uno de estos cree un log por separado, si a esto le sumamos que cada Microservicios podría tener 3, 6, 10 o más instancias, nos llevaría un escenarios caóticos, donde analizar la traza completa de ejecución de una sola ejecución nos podría llevar a analizar decenas o cientos de logs, lo cual es una verdadera locura.
Otro de los problemas que se presenta es que, aunque tengamos ya todos los archivos concentrados en una sola carpeta para analizarlos, es complicado saber que fragmento del log corresponde con una ejecución concreta, lo que nos llevaría a tener que filtrar los archivos por rangos de fecha y hora para tener una aproximación de cómo se realizó la ejecución.
Solución
Para solucionar este problema tenemos el patrón Log aggregation, el cual nos permite que, por medio de un componente externo, podamos concentrando los logs en una sola fuente de datos que podemos consultar más adelante sin la necesidad de tener acceso físico a los servidores y sin importar cuantas instancias de cada componente tengamos.
Lo primero que tenemos que hacer para solucionar este problema es identificar qué información es relevante para el monitoreo de la aplicación, ya que la gran mayoría de la información que inviamos a los logs es basura, por lo que debemos ser cuidadosos para seleccionar que datos son necesario y cuáles no, la regla básicamente es que mandemos lo suficiente para comprender que está pasando, pero tampoco de menos que perdamos la trazabilidad. Una vez identificada la información a enviar, solo hay que enviarla al aggregator para que comience a persistir la información.
Log aggregation
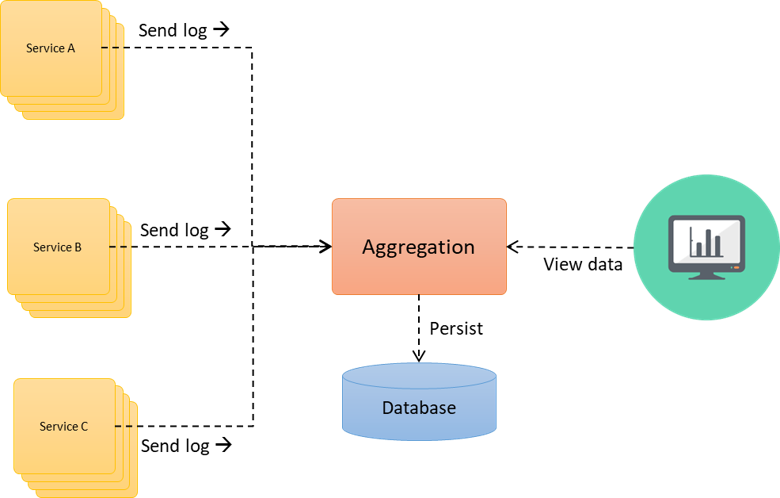
En la imagen anterior podemos apreciar el rol central que juega el Log Aggregation en la arquitectura, pues todos los Microservicios van enviando detalles de la ejecución a medida que son ejecutados.
Algo a tomar en cuenta es que para que el log sea efectivo, es importante identificar cada ejecución de cada Microservicio por separado, pero más importante aún es, identificar todos los Microservicios que se ejecutaron como parte de una solo invocación, por lo que cada Microservicio registra el log con dos valores que ayudan a rastrear la ejecución, el primero es un identificador global de la transacción, el cual comparte todos los Microservicios que se ejecutan como parte de la misma llamada, y el segundo valor es un identificar único por operación, de esta forma, podemos saber todo el log producido por un sola operación y el log producido por toda la transacción.
Una vez que tenemos toda la información concreada en un solo lugar, es posible consultarlas de forma gráfica, lo que permite que cualquier desarrollador puedan consultarla sin tener que tener acceso a los servidores o tener que solicitar a un administrador que le envíe los logs.
La forma en que mandamos la traza al Log Aggregation puede variar, pues hay productos ya desarrollados que permiten mandar los logs de forma síncrona por HTTP, otros permite el envío de información mediante colas de mensajes, otro, permiten enviar los archivos de log como tal, por lo que no existe una única forma de hacerlo, de la misma forma, la forma en que la información se guarda en el Log Aggregation también puede variar, hay algunos que lo guardan en basas de datos relacionales, otros en NoSQL, e incluso, hay casos que son en Memoria.
Conclusiones
Como hemos podido analiza en esta sección, contar con herramientas para centralizar las trazas nos puede dar grandes ventajas al momento de analizar lo que está pasado en nuestra aplicación, ya que nos permite encontrar los errores de una forma más eficiente, dándole una mejor atención a nuestros clientes.
Otra de las ventajas, es que los programadores no necesitan acceso al sistema operativo de todos los servidores para poder recuperar el log, lo que proporciona una mejor seguridad y hace que ellos mismo puedan analizar los errores sin necesidad de que alguien más les proporciones los archivos de logs.
Acerca de este libro
Todo lo que acabas de ver en este artículo es solo una pequeña parte del libro Introducción a la arquitectura de software, el libro más completo en español sobre arquitectura de software, donde cubrimos los temas más importantes para convertirte en un arquitecto de software profesional.
¿Quieres convertirte en arquitecto de software pero no sabes cuál es el camino adecuando? o simplemente no sabes que guía estudiar para convertirte en arquitecto de software, te invito a que veas mi libro: