Cliente-Servidor es uno de los estilos arquitectónicos distribuidos más conocidos, el cual está compuesto por dos componentes, el proveedor y el consumidor. El proveedor es un servidor que brinda una serie de servicios o recursos los cuales son consumido por el Cliente.
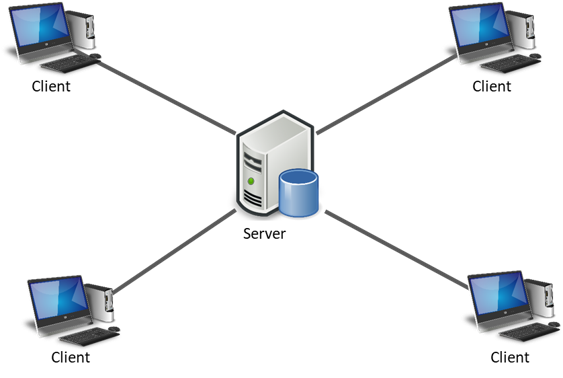
En una arquitectura Cliente-Servidor existe un servidor y múltiples clientes que se conectan al servidor para recuperar todos los recursos necesarios para funcionar, en este sentido, el cliente solo es una capa para representar los datos y se detonan acciones para modificar el estado del servidor, mientras que el servidor es el que hace todo el trabajo pesado.
Arquitectura Cliente-Servidor
En esta arquitectura, el servidor deberá exponer un mecanismo que permite a los clientes conectarse, que por lo general es TCP/IP, esta comunicación permitirá una comunicación continua y bidireccional, de tal forma que el cliente puede enviar y recibir datos del servidor y viceversa.
Creo que es bastante obvio decir que en esta arquitectura el cliente no sirve para absolutamente nada si el servidor no está disponible, mientras que el servidor por sí solo no tendría motivo de ser, pues no habría nadie que lo utilice. En este sentido, las dos partes son mutuamente dependientes, pues una sin la otra no tendría motivo de ser.
Cliente-Servidor es considerada una arquitectura distribuida debido a que el servidor y el cliente se encuentran distribuidos en diferentes equipos (aunque podrían estar en la misma máquina) y se comunican únicamente por medio de la RED o Internet.
En esta arquitectura, el Cliente y el Servidor son desarrollados como dos aplicaciones diferentes, de tal forma que cada una puede ser desarrollada de forma independiente, dando como resultado dos aplicaciones separadas, las cuales pueden ser construidas en tecnologías diferentes, pero siempre respetando el mismo protocolo de comunicación para establecer comunicación.
La idea central de separar al cliente del servidor radica en la idea de centralizar la información y la separación de responsabilidades, por una parte, el servidor será la única entidad que tendrá acceso a los datos y los servirá solo a los clientes del cual el confía, y de esta forma, protegemos la información y la lógica detrás del procesamiento de los datos, además, el servidor puede atender simultáneamente a varios clientes, por lo que suele ser instalado en un equipo con muchos recursos. Por otro lado, el cliente suele ser instalado en computadoras con bajos recursos, pues desde allí no se procesa nada, simplemente actúa como un visor de los datos y delega las operaciones pesadas al servidor.
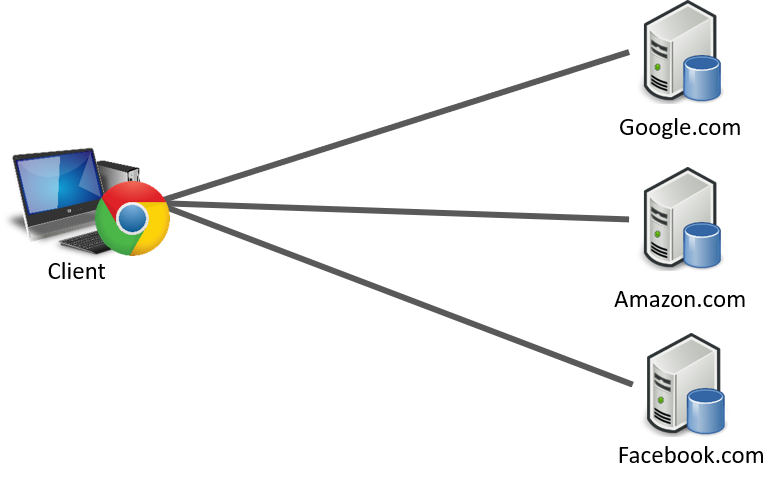
Quizás uno de los puntos más característicos de la arquitectura Cliente-Servidor es la centralización de los datos, pues el server recibe, procesa y almacena todos los datos provenientes de todos los clientes. Si bien los clientes por lo general solo se conectan a un solo servidor, existen variantes donde hay clientes que se conectan a múltiples servidores para funcionar, tal es el caso de los navegadores, los cuales, para consultar cada página establece una conexión a un servidor diferentes, pero al final es Cliente-Servidor:
Múltiples servidores por cliente.
Como podemos ver en la imagen, el navegador actúa como un cliente, pero en lugar de conectarse a un solo servidor, puede conectarse a múltiples servidores. Por otro lado, el navegador no sirve para absolutamente nada sin no podemos acceder a un servidor.
Como se estructura un Cliente-Servidor
Como ya lo mencionamos, el cliente y el servidor son aplicaciones diferentes, por lo que pueden tener un ciclo de desarrollo diferente, así como usar tecnologías y un equipo diferente entre sí. Sin embargo, en la mayoría de los casos, el equipo que desarrolla el servidor también desarrolla el cliente, por lo que es normal ver que el cliente y el servidor están construidos con las mismas tecnologías.
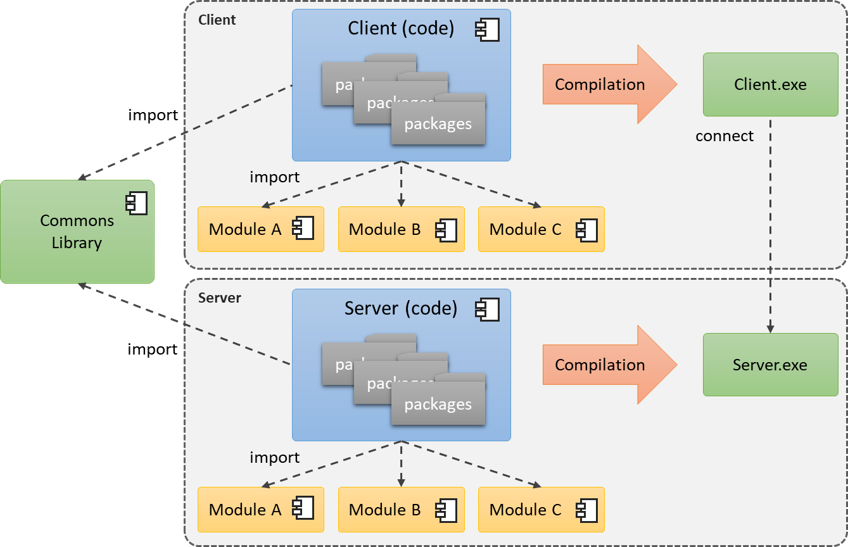
Como podemos ver en la imagen de abajo, el cliente y el servidor son construidos en lo general como Monolíticos, donde cada desarrollo crea su propio ejecutable único y funciona sobre un solo equipo, con la diferencia de que estas aplicaciones no son autosuficientes, ya que existe una dependencia simbiótica entre los dos.
En este sentido, es normal tener 3 artefactos, el Cliente, el Servidor y una tercera librería que contiene Objetos comunes entre el servidor y el cliente, esta librería tiene por lo general los Objetos de Entidad, DTO, interfaces y clases base que se usan para compartir la información, es decir, objetos que se utilizan en las dos aplicaciones y se separan para no repetir código (Principio DRY – Don’t repeat yourself), sin embargo, este tercer componente no es obligatorio que exista, sobre todo si el cliente y el servidor utilizan tecnologías diferentes o son implementados con diferentes proveedores.
Estructura de una aplicación Cliente-Servidor.
Sin importar como desarrollemos el cliente y el servidor, lo importante es notar que siempre existirán un cliente y un servidor, donde el cliente expone la funcionalidad y el cliente la consume.
Ventajas
Centralización: El servidor fungirá como única fuente de la verdad, lo que impide que los clientes conserven información desactualizada.
Seguridad: El servidor por lo general está protegido por firewall o subredes que impiden que los atacantes pueden acceder a la base de datos o los recursos sin pasar por el servidor.
Fácil de instalar (cliente): El cliente es por lo general una aplicación simple que no tiene dependencias, por lo que es muy fácil de instalar.
Separación de responsabilidades: La arquitectura cliente-servidor permite implementar la lógica de negocio de forma separada del cliente.
Portabilidad: Una de las ventajas de tener dos aplicaciones es que podemos desarrollar cada parte para correr en diferentes plataformas, por ejemplo, el servidor solo en Linux, mientras que el cliente podría ser multiplataforma.
Desventajas
Actualizaciones (clientes): Una de las complicaciones es gestionar las actualizaciones en los clientes, pues puede haber muchos terminales con el cliente instalado y tenemos que asegurar que todas sean actualizadas cuando salga una nueva versión.
Concurrencia: Una cantidad no esperada de usuarios concurrentes puede ser un problema para el servidor, quien tendrá que atender todas las peticiones de forma simultánea, aunque se puede mitigar con una estrategia de escalamiento, siempre será un problema que tendremos que tener presente.
Todo o nada: Si el servidor se cae, todos los clientes quedarán totalmente inoperables.
Protocolos de bajo nivel: Los protocolos más utilizados para establecer comunicación entre el cliente y el servidor suelen ser de bajo nivel, como Sockets, HTTP, RPC, etc. Lo que puede implicar un reto para los desarrolladores.
Depuración: Es difícil analizar un error, pues los clientes están distribuidos en diferentes máquinas, incluso, equipos a los cuales no tenemos acceso, lo que hace complicado recopilar la traza del error.
Conclusiones
A pesar de que el estilo Cliente-Servidor no es muy popular entre los nuevos desarrolladores, la realidad es que sigue siendo parte fundamental un muchas de las arquitecturas de hoy en día, solo basta decir que todo el internet está basado en Cliente-Servidor, sin embargo, no es común que como programadores o arquitectos nos encontremos ante problemáticas que requieran implementar un Cliente-Servidor, ya que estas arquitecturas están más enfocadas a aplicaciones CORE o de alto rendimiento, que por lo general es encapsulado por un Framework o API.
A pesar de que puede que no te toque implementar una arquitectura Cliente-Servidor pronto, sí que es importante entender cómo funciona, pues muchas de las herramientas que utilizamos hoy en día implementan este estilo arquitectónico y ni nos damos cuenta, como podrían ser la base de datos, internet, sistemas de mensajería (JMS, MQ, etc), correo electrónico, programas de chat tipo Skype, etc.
La realidad es que Cliente-Servidor es la base sobre la que está construida gran parte de la infraestructura tecnológica que hoy tenemos, pero apenas somos capaces de darnos cuenta.
Acerca de este libro
Todo lo que acabas de ver en este artículo es solo una pequeña parte del libro Introducción a la arquitectura de software, el libro más completo en español sobre arquitectura de software, donde cubrimos los temas más importantes para convertirte en un arquitecto de software profesional.
¿Quieres convertirte en arquitecto de software pero no sabes cuál es el camino adecuando? o simplemente no sabes que guía estudiar para convertirte en arquitecto de software, te invito a que veas mi libro: